Part 3 of How We Built an AI-Powered Document Compliance Engine: The AI Pipeline

Tatjana Petkovska
AI Tech Lead | Architect
Tatjana Petkovska is a Machine Learning Team Lead | Architect at ITQuarks, specializing in Generative AI, Large Language Models, and Computer Vision. She leads the design and delivery of AI-powered solutions that transform complex business problems into scalable, production-ready systems. Her work focuses on building intelligent applications, multi-agent workflows, document intelligence systems, and machine learning pipelines that combine strong engineering practices with practical AI innovation. At ITQuarks, Tatjana plays a key role in guiding AI initiatives from research and experimentation to real-world implementation, helping clients adopt AI in a reliable, measurable, and business-focused way.
Reading time
4 min read
Published
May 18, 2026
Updated
June 2, 2026
Inside the DocuGenius AI pipeline: secure PDF ingestion, paragraph-level chunking, pgvector semantic search, retrieval-augmented generation, and multi-agent LLM extraction for compliance.
Part 3 of a 6-part series on building DocuGenius, an AI-powered document compliance engine for document workflow automation across regulated industries.
← Back to Part 2: The Problem & Architecture
TL;DR: The core of DocuGenius is an AI pipeline that turns an unstructured PDF into structured, evidence-backed compliance verdicts. It finds the evidence relevant to each compliance criterion, evaluates each criterion independently and in parallel, and merges the results into a single structured output. This post covers what each stage does and why it matters for compliance review.
The Processing Pipeline
Once a document lands in the system and a processing job is queued (the asynchronous, Lambda-to-Fargate flow covered in Part 2), the worker transforms a raw PDF into structured compliance verdicts: it finds the evidence relevant to each criterion, evaluates the criteria, and merges the results into a single structured output.
From PDF to Relevant Evidence
Once the worker picks up a queued job, the document is converted into searchable text with page references preserved, fingerprinted so an identical document can be reused safely instead of reprocessed, and indexed so the system can find the passages most relevant to any given compliance criterion.
When a criterion is evaluated, the system retrieves only the passages relevant to that criterion rather than feeding the whole document to the model. Keeping retrieved context focused, and tied back to its source page, improves accuracy, keeps evidence highlighting straightforward, and keeps processing costs predictable.
Context Isolation Inside The Pipeline
Part 2 covers the platform-level security model, including encrypted storage, tenant separation, AWS trust boundary, and minimal logging. Inside the AI pipeline itself, one principle shapes the design: each processing step sees only the minimum context it needs. No single step holds the whole document, so evaluating one criterion at a time is a privacy property as much as a performance one.
Multi-Agent Extraction
This is the core of the system. Rather than sending one massive prompt with every criterion and every page to a single model call, the platform evaluates each compliance criterion independently and in parallel, then merges the results into a single validated, structured output.
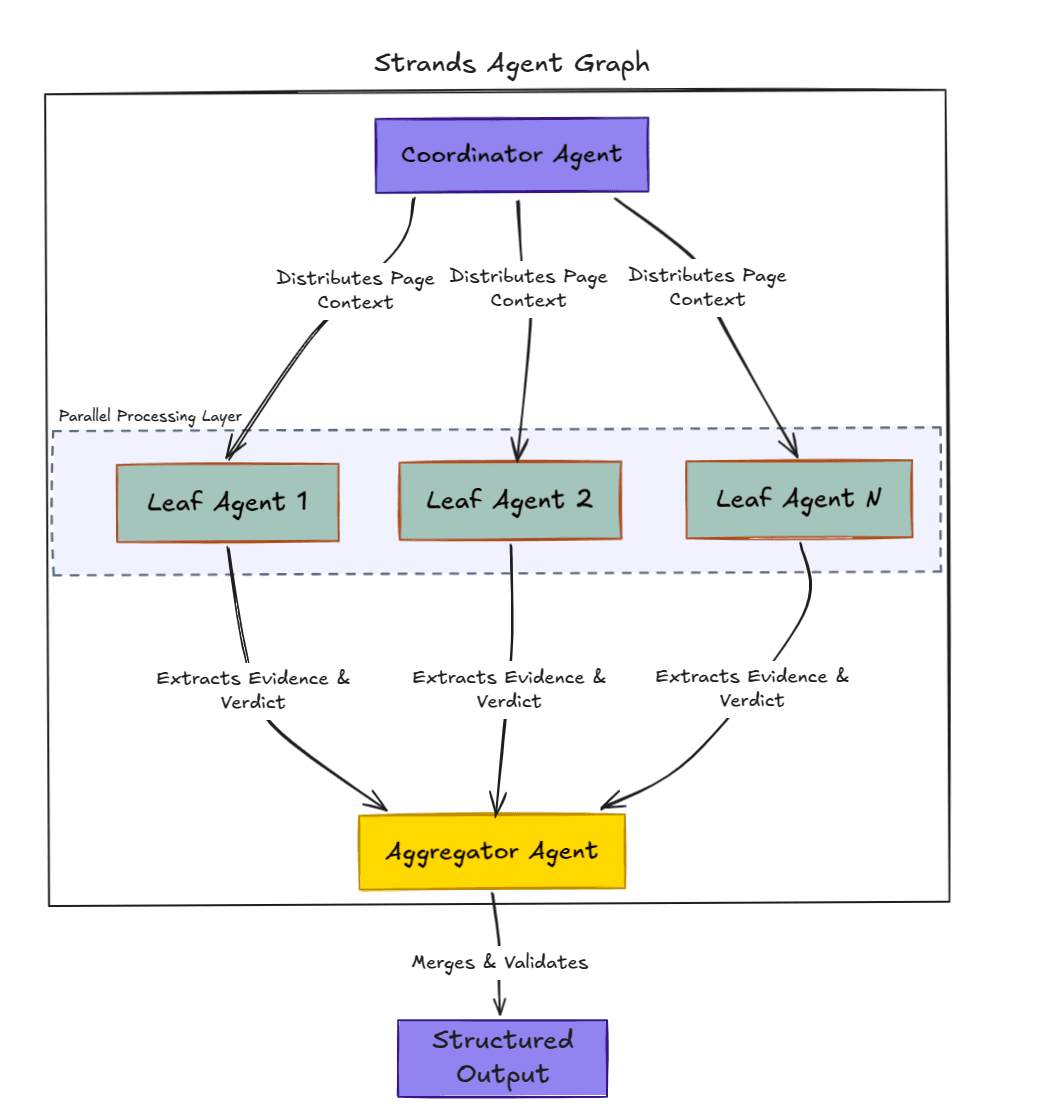
Figure 1: The Strands agent graph. The Coordinator distributes page context to parallel Leaf Agents, which independently extract evidence and verdicts. The Aggregator merges and validates all results into a single structured output.
Why Evaluate One Criterion At A Time?
Handling each criterion on its own keeps every evaluation focused, lets different criteria be tuned for their own domain without code changes, and isolates failures: if one criterion can't be resolved, the others still complete, so reviewers get partial results instead of a failed job.
The trade-off is latency: many focused evaluations run instead of one large call. They run concurrently, and a typical 20-criterion review completes in 40-90 seconds, well within range for an asynchronous workflow.
Acknowledgement
This work was shaped by the engineering effort behind DocuGenius, built by the team at ITQuarks, whose product thinking, implementation, and delivery discipline were instrumental in bringing the platform to life.
Suggested CTA
If you're stress-testing an AI document review pipeline against real claims, eligibility, or supplier files, we'd be glad to compare notes on what scales and what breaks. Talk to the DocuGenius team.
What's Next
With raw evidence extracted from each page, the system still needs to make a final compliance decision. In Part 4, we cover how boolean tree evaluation turns individual LLM verdicts into a top-level compliance outcome, how we highlight the exact evidence in the PDF using fuzzy matching, and how the DMN rule engine lets compliance teams define new rule sets without writing code.
Part 4: Evaluation, Evidence Highlighting & the DMN Rule Engine is live now. Follow DocuGenius on LinkedIn to get notified for the rest of the series, or bookmark the blog.
Tatjana Petkovska
AI Tech Lead | Architect
Tatjana Petkovska is a Machine Learning Team Lead | Architect at ITQuarks, specializing in Generative AI, Large Language Models, and Computer Vision. She leads the design and delivery of AI-powered solutions that transform complex business problems into scalable, production-ready systems. Her work focuses on building intelligent applications, multi-agent workflows, document intelligence systems, and machine learning pipelines that combine strong engineering practices with practical AI innovation. At ITQuarks, Tatjana plays a key role in guiding AI initiatives from research and experimentation to real-world implementation, helping clients adopt AI in a reliable, measurable, and business-focused way.