How We Built an AI-Powered Document Compliance Engine - Part 2: The Problem & Architecture

Tatjana Petkovska
AI Tech Lead | Architect
Tatjana Petkovska is a Machine Learning Team Lead | Architect at ITQuarks, specializing in Generative AI, Large Language Models, and Computer Vision. She leads the design and delivery of AI-powered solutions that transform complex business problems into scalable, production-ready systems. Her work focuses on building intelligent applications, multi-agent workflows, document intelligence systems, and machine learning pipelines that combine strong engineering practices with practical AI innovation. At ITQuarks, Tatjana plays a key role in guiding AI initiatives from research and experimentation to real-world implementation, helping clients adopt AI in a reliable, measurable, and business-focused way.
Reading time
10 min read
Published
May 14, 2026
Updated
June 2, 2026
How a verifiable AI document compliance engine uses AWS Lambda, Fargate, Textract, and Bedrock to separate short API requests from long document review jobs without losing the audit trail.

How We Built an AI-Powered Document Compliance Engine - Part 2: The Problem & Architecture
Part 2 of a 6-part series on building DocuGenius, an AI-powered document compliance engine for document workflow automation across regulated industries.
← Back to Part 1: Series Overview
💡 Bookmark this page. We'll update it as each part publishes. New parts drop every 2 days through Tue 2026-05-26 CET.
TL;DR: Compliance review doesn't scale when people read every document against every rule by hand. DocuGenius is built around an asynchronous AWS design. AWS Lambda handles short user actions. AWS Fargate runs long document reviews in the background. Amazon Textract handles OCR. Amazon Bedrock powers the agentic extraction workflow. Each company's data stays separated, and every decision is stored with its evidence. The result: AI document review that operations, compliance, claims, and underwriting teams can defend in an audit that is written here for decision makers, not just engineers.
What is the real problem behind compliance review?
The real problem isn't reading one document. It's reading thousands against detailed rule sets, consistently, with traceable evidence for every answer. That combination of volume, variability, and audit pressure breaks manual review. An AI document compliance engine fixes it: extract evidence, apply rules deterministically, return verdicts with page-level references a reviewer can verify in seconds.
Compliance Review Doesn't Scale With People
In regulated industries such as healthcare, food safety, financial services, logistics, insurance, construction, public sector, compliance teams spend most of their day reading documents. Page by page, they check whether each one satisfies a list of requirements.
A single eligibility review for a medical device like a CPAP machine or a continuous glucose monitor can mean cross-referencing one patient record against 15–30 criteria including diagnosis codes, prescription dates, physician signatures and eligibility windows. The same pattern shows up in claims packets, loan files, driver qualification files, and supplier reviews. Different industries, same shape of problem:
- High document volume
- Detailed, repeatable rules
- Unstructured PDFs as the source material
- An audit trail expected behind every decision
That is a problem shape modern AI is genuinely good at, but only when the answers are verifiable.
Why Current Tools Fall Short
Most teams have already tried something. The patterns repeat:
- Manual review with checklists. Accurate when done well, but slow, expensive, and inconsistent across reviewers.
- OCR plus templates. Works on clean, structured forms. Breaks the moment the document varies and most real-world documents vary.
- Generic LLM chatbots. Useful for summarizing a single file. Not built to evaluate a document against a rule set, return per-criterion verdicts, or show evidence on the source page.
- Custom scripts and one-off automations. Solve a narrow case. Become a maintenance burden when rules change or document types expand.
None of those approaches fail because AI isn't ready. They fail because compliance review is not really a chat problem but a workflow problem, and workflows need structure, traceability, and consistent behavior under load.
What "Good" Looks Like For AI Document Review
Before talking about architecture, it helps to describe the target state in operational terms.
Good looks like this:
- A reviewer drops a document into the platform and walks away.
- Within a short, predictable window, the system returns a structured result.
- Each compliance criterion has a clear verdict: true, false, or unknown.
- Each verdict is backed by extracted evidence and a page reference.
- A highlighted version of the original PDF shows exactly where each answer came from.
- Business teams can update rule sets without filing engineering tickets.
- Operations leaders can see throughput, exceptions, and cycle time at a glance.
That is the brief DocuGenius is built against. The architecture exists to make that brief reliable at volume, not to be impressive in a diagram.
Architecture Overview (At The Level That Matters)
The platform separates two kinds of work that have very different shapes, and leans on managed AWS services so the team can focus on the compliance pipeline instead of plumbing.
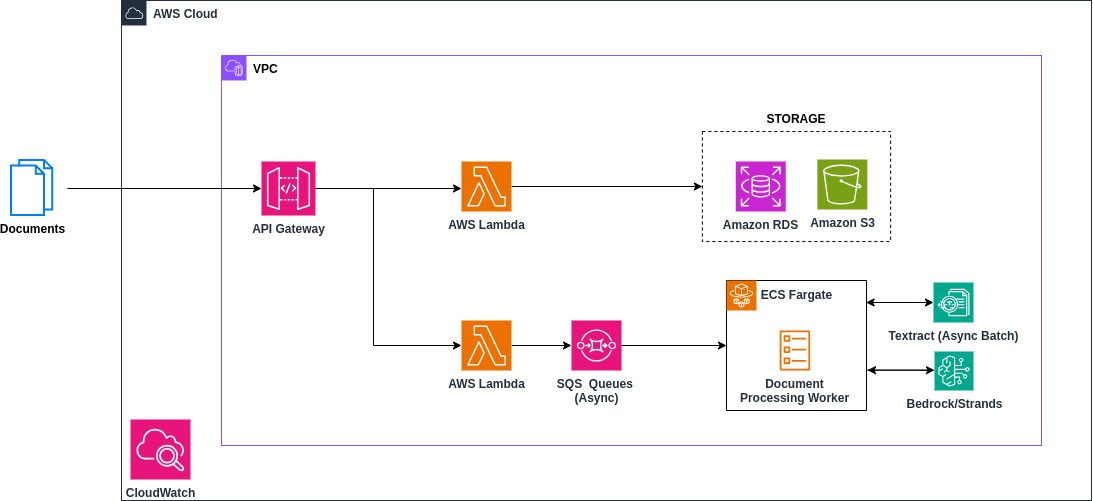
Figure 1: A simplified view of the architecture. Short user actions flow through the Lambda API tier. Long document reviews run asynchronously on Fargate, using Textract for OCR and Bedrock for the agentic workflow. Results are persisted with their evidence for review and audit. Everything runs inside a private AWS VPC.
At a high level, the system has four responsibilities:
- A user-facing API tier on AWS Lambda that handles short, bursty actions such as uploads, status checks, report retrieval.
- An asynchronous work queue that decouples those actions from the actual review work.
- A background processing tier on AWS Fargate that runs the AI document review pipeline reliably, even under spikes by using Amazon Textract for OCR and Amazon Bedrock for the agentic extraction workflow over a configurable rule set.
- A results store that captures verdicts, evidence, page references, and audit metadata for every decision which are kept cleanly separated per customer so each company only sees its own work.
The internals of each layer are deliberate engineering choices we've tuned over time. We don't name every component here because the principle is what matters: short user actions stay fast, long reviews stay reliable, tenants stay separated, and the audit trail stays intact.
Why Lambda For The API, Fargate For The Review
User-facing actions and AI document review have fundamentally different operational profiles.
- User actions are short and bursty: uploads, status checks, report retrieval. They need to feel instant and idle cheaply. AWS Lambda is a clean fit.
- Document reviews are long and resource-intensive. They benefit from a warm execution environment and predictable performance under sustained load. AWS Fargate gives that processing tier a stable place to run, without timeout pressure or cold-start dynamics.
Mixing those profiles into a single tier is where most early AI document automation breaks. A burst of uploads stalls the API. A long review starves a request. A timeout kills a job halfway through.
Decoupling them with an asynchronous queue between keeps the platform predictable under real claims-week, eligibility-cycle, and audit-deadline traffic. Not just under demos.
Why Textract And Bedrock Inside The Pipeline
Inside the Fargate processing tier, two AWS services do most of the heavy lifting:
- Amazon Textract handles OCR and text extraction. Real-world compliance PDFs include scans, faxes, mixed-quality images, and forms. Textract turns those into structured text the rest of the pipeline can reason over, without standing up a custom OCR stack.
- Amazon Bedrock powers the agentic extraction workflow. Compliance review isn't a single prompt. It's a coordinated set of steps across many criteria, each one needing focused reasoning and evidence. Bedrock gives us capable foundation models inside the AWS trust boundary which matters when documents contain sensitive data.
Together, OCR and the agent workflow turn an unstructured PDF into a structured, evidence-backed result. How the pipeline retrieves pages, reasons about each criterion, and stitches outputs into a final decision is the focus of Part 3.
Tenant Separation: Each Company's Work Stays Its Own
Most buyers ask about this early, and rightly so.
DocuGenius keeps each company's documents, results, and processing cleanly separated from every other customer's. A reviewer in one organization can never see another's documents, evidence, or compliance outcomes. Role-based access narrows that further inside an organization, so users only see what they're authorized to review.
That separation matters operationally: reviews stay predictable per customer. It matters for compliance too. Regulated industries expect tenant isolation by default and not as an upsell.
Operational Impact Across Industries
The same architecture maps cleanly across document-heavy verticals:
- Insurance: claims intake, policy reviews, underwriting packets. The work absorbs spikes around quarter close, weather events, and renewal cycles without manual triage.
- Healthcare: eligibility, medical necessity, prior authorization. Reviews complete in predictable windows, freeing clinical and operational staff for higher-value work.
- Financial services: loan file reviews, KYC, supporting document checks. Reviewers get structured verdicts with evidence instead of stitching findings together from scratch.
- Logistics: driver qualification files, DOT documentation, carrier compliance. Periodic re-reviews stop being a quarterly fire drill.
- Food safety, construction, public sector: supplier certifications, HACCP records, grant applications, procurement files. Standardized reviews with consistent evidence trails.
The throughline is the same in every vertical: predictable cycle time on the work itself, less manual triage in the middle, and a defensible audit trail at the end.
Verifiability Is The Product Requirement
The hardest part of document compliance automation is not extracting answers. It is proving where those answers came from.
For every compliance criterion, DocuGenius stores the verdict, the supporting evidence, the source page, the link between evidence and rule, and the final evaluated outcome. A reviewer can open a result and immediately see why the system answered the way it did.
That is the difference between an AI tool that produces an answer and an AI document review platform an operations leader can defend in an audit.
Verifiability is not a feature added at the end. It is the constraint that shapes how data is stored, how results are structured, and how the dashboard surfaces decisions for review which is covered in more depth in Part 4.
Security, Privacy, And Industry Benefits
Security is part of the architecture. The documents reviewed often contain protected health information (PHI), personally identifiable information (PII), financial records, supplier documentation, or driver qualification files. Sensitive data either way.
The system is designed around privacy-first document processing:
- Controlled, encrypted storage: PDFs and reports are kept in tenant-aware, access-controlled, encrypted storage; transport is encrypted end to end.
- AI inside the AWS trust boundary: OCR via Textract and model calls via Bedrock keep document content inside controlled, enterprise-grade AWS services.
- Minimal operational logging: logs cover job status, errors, and timing, never document contents or extracted PHI/PII.
- Structured result storage: verdicts, evidence, and outcomes are saved as structured records reviewers can audit without searching raw logs.
- Role-based access and tenant separation: users only see the documents, reports, and analytics they're authorized to review, scoped to their own organization.
- Retention and deletion readiness: document lifecycle rules and storage separation support retention policies, deletion workflows, and customer-specific data governance.
The practical benefit is the same across HIPAA-aligned healthcare reviews, insurance claims, financial-services loan files, and supplier or driver-qualification reviews. Sensitive documents stay in controlled systems. Results are reviewable. Compliance teams get a faster workflow without losing auditability.
Frequently asked questions
Can our company's data be kept separate from other customers on the platform?
Yes. Each customer is provisioned as an isolated tenant. Documents, processing, and results are scoped to that company alone. One organization can't see another's files, evidence, or outcomes. Inside an organization, role-based access narrows visibility further, so users only see what they're authorized to review.
Are our sensitive documents safe on the platform?
Yes. Documents are processed inside a private VPC on AWS, isolated per customer, and stored in encrypted, access-controlled storage. OCR and AI calls run inside the AWS trust boundary via Textract and Bedrock; document content isn't sent to public AI endpoints.
Acknowledgement
This work was shaped by the engineering effort behind DocuGenius, built by the team at ITQuarks, whose product thinking, implementation, and delivery discipline were instrumental in bringing the platform to life.
Suggested CTA
If you're scoping an AI document review platform for claims, eligibility, lending, supplier compliance, or regulatory review, we're happy to walk through how this architecture maps to your workflow. Talk to the DocuGenius team.
What's Next
In Part 3, we go deeper into the review pipeline itself: how documents are ingested through Textract, how the system retrieves the right pages for each criterion, and how the Bedrock-powered agentic workflow reasons about one compliance question at a time.
Read Part 3: The AI Pipeline - now live. Follow DocuGenius on LinkedIn for the rest of the series as it drops, or bookmark the blog.
Tatjana Petkovska
AI Tech Lead | Architect
Tatjana Petkovska is a Machine Learning Team Lead | Architect at ITQuarks, specializing in Generative AI, Large Language Models, and Computer Vision. She leads the design and delivery of AI-powered solutions that transform complex business problems into scalable, production-ready systems. Her work focuses on building intelligent applications, multi-agent workflows, document intelligence systems, and machine learning pipelines that combine strong engineering practices with practical AI innovation. At ITQuarks, Tatjana plays a key role in guiding AI initiatives from research and experimentation to real-world implementation, helping clients adopt AI in a reliable, measurable, and business-focused way.