How We Built an AI-Powered Document Compliance Engine — Part 1: Series Overview

Tatjana Petkovska
AI Tech Lead | Architect
Tatjana Petkovska is a Machine Learning Team Lead | Architect at ITQuarks, specializing in Generative AI, Large Language Models, and Computer Vision. She leads the design and delivery of AI-powered solutions that transform complex business problems into scalable, production-ready systems. Her work focuses on building intelligent applications, multi-agent workflows, document intelligence systems, and machine learning pipelines that combine strong engineering practices with practical AI innovation. At ITQuarks, Tatjana plays a key role in guiding AI initiatives from research and experimentation to real-world implementation, helping clients adopt AI in a reliable, measurable, and business-focused way.
Reading time
7 min read
Published
May 12, 2026
Updated
May 28, 2026
A practical overview of DocuGenius — an AI document compliance engine using RAG, multi-agent extraction, evidence highlighting, and DMN rules to automate document workflows.
How We Built an AI-Powered Document Compliance Engine - Part 1: Series Overview
This is Part 1 of a 6-part series on building DocuGenius, an AI-powered document compliance engine for document workflow automation across regulated industries.
💡 Bookmark this page. We'll update it as each part publishes. New parts drop every 2 days through Tue 2026-05-26.
TL;DR: DocuGenius is an AI-powered document compliance engine that reads unstructured PDFs, evaluates them against configurable rules, and returns structured verdicts with highlighted evidence. This overview explains the product goal, the architecture, and what each post in the series covers - written for operations, compliance, claims, and underwriting leaders, not just engineers.
What is an AI document compliance engine?
An AI document compliance engine is software that reads unstructured documents, typically PDFs and evaluates them against configurable compliance rules. It returns per-criterion verdicts, extracted evidence, page-level references, and a deterministic final decision that compliance teams can audit, defend, and trust. Unlike a generic LLM chatbot, it shows its work for every answer.
Why We Built DocuGenius
In regulated and document-heavy industries, compliance review is still heavily manual. Teams read documents, compare them against detailed rule sets, and record whether each requirement is satisfied. The work is repetitive, high-volume, expensive and it requires traceability. Every answer needs evidence.
That combination is a strong fit for AI document review, but not for a generic chatbot. A real compliance automation system has to do more than summarize a PDF. It must:
- Extract evidence from unstructured documents
- Evaluate each compliance criterion consistently
- Return page-level references and highlighted source text
- Let business teams change rules without engineering work
- Produce auditable outputs that reviewers can trust
DocuGenius was built around that brief: use LLMs for document understanding, but keep compliance logic, evidence tracking, and rule evaluation explicit and verifiable. The mechanics of that — fuzzy-matched evidence highlighting and a no-code DMN rule engine — are the focus of Part 4 of this series.
For search and discovery, the category is AI document compliance software for teams that need automated document review, evidence extraction, compliance checks, and defensible regulatory document processing. The goal is not generic AI summarization. The goal is reliable document automation a reviewer can verify in seconds.
What The System Does
At a high level, DocuGenius accepts a PDF and a compliance rule set, and returns:
- Per-criterion verdicts: true, false, or unknown
- Extracted supporting evidence for each answer
- Page references and highlighted PDF annotations
- A deterministic top-level compliance decision
- Structured results that can be reviewed in a dashboard or exported
The platform runs on AWS using API Gateway, Lambda, SQS FIFO queues, ECS Fargate, S3, PostgreSQL, pgvector, and a multi-agent orchestration layer. The AI pipeline combines retrieval-augmented generation (RAG), page-level embeddings, parallel LLM extraction, and deterministic rule evaluation. How that pipeline works step-by-step including the multi-agent extraction graph that handles one compliance criterion at a time which is the focus of Part 3 of this series.
Architecture At A Glance
The architecture separates short API requests from long-running document processing jobs.
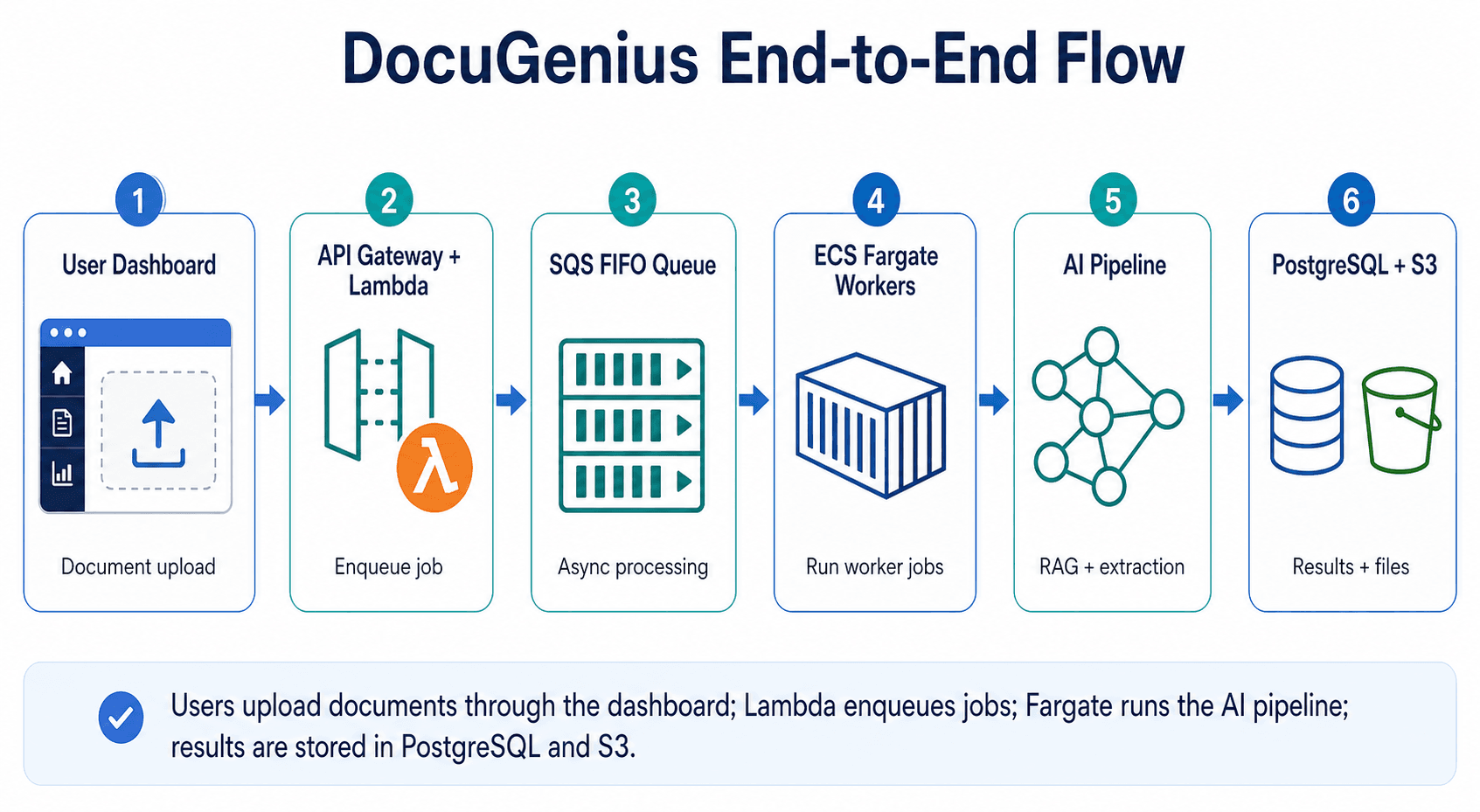
Figure 1: DocuGenius end-to-end flow. Users upload documents through the dashboard, API Gateway and Lambda enqueue processing jobs, ECS Fargate workers run the AI pipeline, and results are stored in PostgreSQL and S3.
The core design principle is separation of responsibilities:
- Lambda handles API operations - upload requests, job status checks, report retrieval.
- SQS FIFO queues decouple ingestion from processing - document jobs run asynchronously, so a spike doesn't stall the API.
- ECS Fargate handles long-running AI workloads - without Lambda timeout or cold-start constraints.
- PostgreSQL and pgvector store structured data and embeddings - enabling semantic page retrieval.
- The multi-agent LLM pipeline extracts evidence - one compliance criterion at a time.
- The DMN rule engine evaluates business logic - deterministically and auditable.
The reasoning behind each of these choices - particularly the Lambda / Fargate split between short API calls and long AI jobs — is unpacked in Part 2 of this series.
.
What This Series Covers
Part 2: The Problem & Architecture - why manual compliance review doesn't scale, why verifiable AI matters, and why we chose a Lambda/Fargate split for AWS document processing.
Part 3: The AI Pipeline - PDF ingestion, page-level embeddings, semantic retrieval with pgvector, and multi-agent LLM extraction with Strands.
Part 4: Evaluation, Evidence Highlighting & DMN - how raw LLM outputs become deterministic compliance decisions, how highlighted PDFs are generated, and why DMN makes rule management no-code.
Part 5: Cost Optimization, Dashboard & Results - content-based caching, the Next.js dashboard, production metrics, and the operational choices that made the system affordable.
Part 6: Lessons Learned & What's Next - the most important engineering lessons, the roadmap, and final takeaways for teams building compliance automation.
Who This Is For
This series is written for decision-makers and technical stakeholders, including Operations Directors, compliance teams, claims departments, underwriting teams, regulatory leaders, and technical leads responsible for evaluating, implementing, or scaling AI-powered compliance review systems.
The implementation details are specific to DocuGenius, but the patterns apply broadly for healthcare eligibility review, insurance claims intake, loan application review, food safety audits, logistics compliance, supplier review, grant evaluation, and other document-heavy workflows.
The rest of the series gets technical where it matters. We cover the AWS architecture, the RAG pipeline, multi-agent extraction, rule evaluation, evidence highlighting, cost control, and the trade-offs we ran into in production.
Frequently asked questions
What is an AI-powered document compliance engine?
An AI-powered document compliance engine reads unstructured documents and evaluates them against configurable rules. It returns per-criterion verdicts, evidence, and page references — so compliance teams can audit every decision instead of trusting an AI summary.
How is this different from using a general LLM chatbot on PDFs?
A general LLM chatbot can summarize a document, but it cannot reliably evaluate it against a structured rule set, return deterministic verdicts, or show evidence on the source page. A compliance engine adds rule evaluation, evidence highlighting, audit trails, and configurable rule sets on top of the LLM.
Which industries use AI document compliance automation?
The most common verticals are insurance (claims, underwriting), healthcare (eligibility, medical necessity review), financial services (loan files, KYC), logistics (driver qualification, DOT files), food safety (HACCP, FSMA), construction (supplier certifications), and the public sector (grants, procurement).
Is AI document review safe for sensitive data?
When the architecture is designed for it - yes. The system needs controlled storage, encrypted transport, minimal operational logging, role-based access, retention policies, and structured result storage rather than treating logs as a record. We cover this in Part 2 .
How long does AI document compliance review take?
Typical end-to-end processing for a 15-page document against 20 compliance criteria runs 45 to 90 seconds. With content-based caching, repeat documents return in sub-second time. Production benchmarks are in Part 5 .
Acknowledgement
This work was shaped by the engineering effort behind DocuGenius, built by the team at ITQuarks, whose product thinking, implementation, and delivery discipline were instrumental in bringing the platform to life.
Suggested CTA
If your team is exploring AI document automation for claims, eligibility, underwriting, or compliance — we're happy to walk you through how this architecture maps to your workflow. Talk to the DocuGenius team.
What's Next
In Part 2, we go deeper into the original problem and the architecture decisions behind the system: why manual compliance review breaks down, why verifiability matters, and why the processing tier runs on Fargate instead of Lambda.
Read Part 2: The Problem & Architecture - now live. Follow DocuGenius on LinkedIn for the rest of the series as it drops, or bookmark the blog.
Tatjana Petkovska
AI Tech Lead | Architect
Tatjana Petkovska is a Machine Learning Team Lead | Architect at ITQuarks, specializing in Generative AI, Large Language Models, and Computer Vision. She leads the design and delivery of AI-powered solutions that transform complex business problems into scalable, production-ready systems. Her work focuses on building intelligent applications, multi-agent workflows, document intelligence systems, and machine learning pipelines that combine strong engineering practices with practical AI innovation. At ITQuarks, Tatjana plays a key role in guiding AI initiatives from research and experimentation to real-world implementation, helping clients adopt AI in a reliable, measurable, and business-focused way.